- Accueil /
- IA explicable utilisant des transformateurs de vision sur des images de maladies de la peau
IA explicable utilisant des transformateurs de vision sur des images de maladies de la peau
Shanel Gauthier, Data Scientist
Jeudi, 15 septembre 2022
Au cours de la dernière décennie, nous avons assisté à des avancées considérables dans le domaine de l'apprentissage profond. Le domaine médical a bénéficié de toutes ces avancées où divers systèmes de diagnostic assisté par ordinateur (DAO) ont été proposés pour aider et faciliter la tâche des médecins.
Oro Health fournit des outils aux professionnels de la santé pour créer leur présence virtuelle. Très tôt, Oro Health a décidé de développer des solutions d'IA dans le domaine médical. Les bases d'Oro Health ont été posées par la naissance de Dermago qui permet aux patients de consulter un dermatologue depuis le confort de leur maison. Ainsi, nous avons concentré nos efforts sur la réalisation d'expériences robustes pour classifier les images de maladies de la peau à partir de données du monde réel.
Après plusieurs conversations avec des dermatologues, il est apparu clairement que l'explication de l'IA est un élément clé pour que les médecins fassent confiance aux modèles d'apprentissage profond. Mais qu'est-ce que l'applicabilité de l'IA ? Sur le site frontiersin.org, on la définit comme suit : " un ensemble d'outils et de cadres qui peuvent aider à comprendre et à interpréter les prédictions de l'apprentissage automatique (ML) " [1].
Pour les dermatologues, il peut être difficile de faire confiance à un outil qu'ils ne comprennent pas. Il est donc crucial de pouvoir expliquer pourquoi un modèle prend une décision. Nous nous concentrons donc sur ce sujet pour améliorer la compréhension de nos solutions d'IA.
Applicabilité en vision par ordinateur
Le réseau neuronal convolutif (CNN) est un algorithme d'apprentissage profond largement utilisé dans le domaine de la vision par ordinateur (VA), qui prend en compte les informations spatiales des images. Diverses techniques ont été développées pour visualiser les zones de l'image qui contribuent le plus aux prédictions du CNN. Ces techniques sont utilisées pour visualiser le processus de décision des modèles profonds.
La plupart des techniques de visualisation appartiennent à l'une de ces deux classes : les méthodes de gradient et les méthodes d'attribution [2]. Les méthodes basées sur le gradient reposent sur la rétropropagation à travers un CNN pour calculer les gradients par rapport à l'entrée de chaque couche. De nombreuses techniques de cette catégorie sont implémentées dans le package PyTorch grad-cam. La deuxième catégorie de méthodes, les "méthodes d'attribution", est basée sur le cadre de la décomposition profonde de Taylor (DTD).
Approche proposée
En 2022, les modèles de transformation de la vision (ViT) sont maintenant largement utilisés dans une variété de tâches de vision par ordinateur et sont considérés comme une alternative compétitive aux CNN [3]. Le ViT est constitué de mécanismes d'attention (couches d'auto-attention) qui attribuent des valeurs d'attention par paire entre deux patchs d'image.
Avec les techniques précédemment évoquées pour générer des cartes de pertinence, il n'est pas clair comment appliquer ces méthodes aux patchs d'images discrets utilisés dans les ViTs. Chefer et al. [2] proposent, dans leur article sur l'interprétabilité des transformateurs au-delà de la visualisation de l'attention, une nouvelle façon de visualiser les parties d'une image qui ont conduit à une classification en utilisant des modèles basés sur les transformateurs. Leur approche donne des résultats de pointe par rapport à diverses méthodes et est basée sur l'attribution de scores de pertinence locaux en utilisant le principe de la DTD et en propageant les scores à travers toutes les couches [2].
Tâche de classification appliquée aux images de maladies de la peau : Notre tutoriel étape par étape
L'approche proposée [2] est accompagnée d'un dépôt GitHub [4]. Dans ce dépôt, les auteurs ont inclus un carnet de notes pour démontrer comment créer les visualisations.
Dans cette section, nous donnons un tutoriel étape par étape sur la façon dont nous utilisons leur code pour visualiser les parties d'une image qui ont conduit à une prédiction en utilisant notre classificateur de maladies de la peau. Notez que nous utilisons le cadre PyTorch.
Nous utilisons un modèle ViT, pré-entraîné sur ImageNet-1k. Le ViT est l'algorithme qui donne les meilleures performances pour notre tâche jusqu'à présent. Nous affinons le modèle pour notre tâche spécifique qui consiste à classer les maladies de la peau sur des images du monde réel. Dans notre expérience, nous utilisons le référentiel Timm [5] pour affiner un modèle ViT pré-entraîné.
Le paquetage Timm permet d'affiner très facilement un modèle pré-entraîné, ce qui nous facilite la tâche.
Ensuite, nous devons sauvegarder le dictionnaire d'état.
Maintenant que nous avons affiné un modèle ViT pour classer les images de maladies de la peau et sauvegardé son dictionnaire d'état, l'étape suivante consiste à cloner le référentiel qui contient l'implémentation pour générer les visualisations souhaitées [4].
Pour notre tâche, le modèle a été affiné pour classer 41 maladies de la peau. Notre équipe travaille sur ce classificateur depuis plus de deux ans maintenant. À l'origine, le nombre de classes était de 15. Depuis, nous avons eu accès à davantage d'images. Plus le nombre de classes est important, plus le classificateur sera utile.
L'étape suivante consiste à créer un dictionnaire pour associer les nombres ordonnés commençant par 0 au nom de la maladie qui leur est associée. Avant d'envoyer les images au réseau neuronal, nous les normalisons en utilisant la moyenne et l'écart-type d'ImageNet-1k.
Dans nos expériences précédentes, nous avons initialement utilisé le modèle ViT du paquet Timm [5] et sauvegardé le dictionnaire d'état du modèle ajusté. Encore une fois, nous avons insisté sur l'utilisation du paquetage Timm pour le réglage fin de notre modèle en raison de sa simplicité.
Pour générer les visualisations souhaitées, nous avons voulu utiliser le référentiel de Chefer et al [2].
Nous créons une liste qui contient les chemins vers les images pour lesquelles nous voulons générer les visualisations.
Évidemment, pour des raisons de confidentialité, nous ne sommes pas autorisés à montrer les images de notre ensemble de données. Nous avons donc dû réfléchir aux images que nous pourrions montrer dans ce blog. C'est alors que j'ai eu une idée ! Dans ma famille, nous avons beaucoup de maladies de peau, y compris moi-même. J'ai donc demandé aux membres de ma famille si je pouvais utiliser leurs images et les soumettre au ViT affiné pour voir quelles parties de l'image contribuent le plus à la prédiction. Ils ont tous accepté et étaient très enthousiastes. Pour la première fois de ma vie, j'étais heureux d'avoir une famille avec des problèmes de peau !
Parmi toutes les images que ma famille m'a envoyées, j'en ai sélectionné cinq. J'ai veillé à inclure des images comportant beaucoup d'arrière-plan pour voir si l'arrière-plan contribue à la décision du modèle. L'ensemble de données utilisé pour affiner le modèle contient des images de maladies de la peau prises par les patients eux-mêmes. Dans certains cas, nous observons beaucoup d'informations de fond.
Les images sélectionnées sont présentées ci-dessous.
Images de maladies de la peau
C'est maintenant le moment que nous attendions : la génération des cartes de pertinence.
Analyse des cartes de pertinence
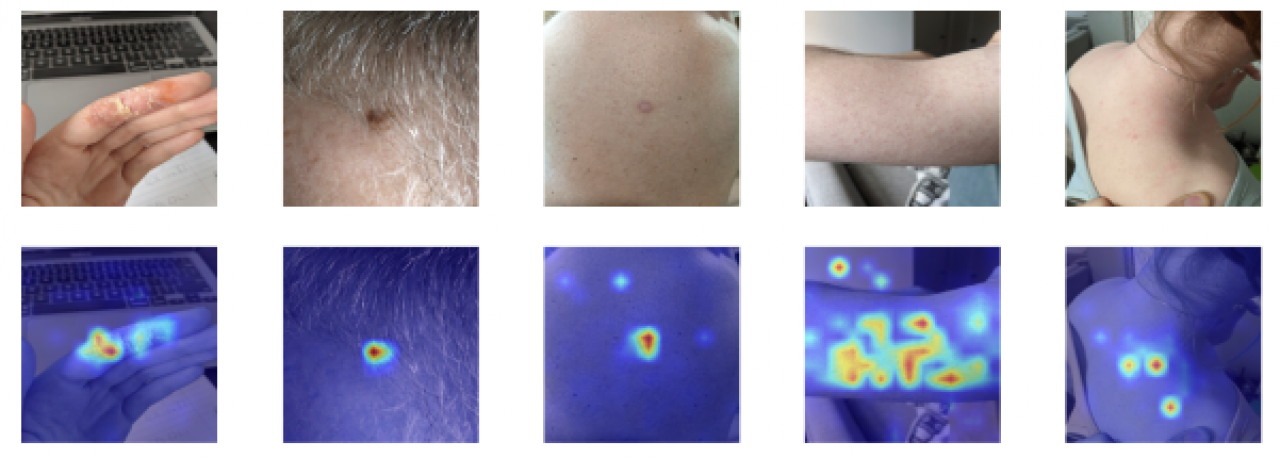
Les cartes générées sont présentées ci-dessous. La première chose que nous avons voulu vérifier est que l'arrière-plan contribue aux prédictions. Seule la zone de peau affectée devrait contribuer à la classification. Nous observons que c'est le cas pour les cinq images.
Cartes d'attention des images de maladies de la peau utilisant ViT
Dans la première image, nous observons beaucoup d'informations sur l'arrière-plan. Nous pouvons discerner le clavier d'un ordinateur portable et une feuille de papier. Cependant, seul le doigt affecté présente des couleurs chaudes sur la carte de pertinence. Cela confirme que le modèle utilise les bonnes informations pour prendre sa décision.
Même si la lésion cutanée, dans la deuxième image, est partiellement recouverte de poils, les couleurs chaudes se trouvent uniquement sur cette région. C'est exactement ce que nous voulons. Encore une fois, dans la troisième image, les couleurs chaudes sont uniquement sur la zone affectée.
Dans la quatrième image, nous observons beaucoup plus de régions avec des couleurs chaudes. Cette personne souffre de kératose pilaire, également connue sous le nom de "peau de poulet". Sur l'image, toute la peau est touchée. Les couleurs chaudes se trouvent principalement sur la peau, ce qui correspond à nos attentes. Cependant, il y a un petit cercle de couleurs chaudes sur le fond, mais il est négligeable. L'important est que l'attention se porte principalement sur la peau, ce qui est le cas.
Dans la cinquième image, la personne a des taches rouges près de son épaule droite. Nous pouvons discerner quelques informations sur le fond. Malgré cela, les couleurs chaudes sont sur la région de la peau affectée.
Conclusion
En conclusion, nous avons présenté un tutoriel étape par étape sur la façon dont nous avons utilisé l'approche proposée par Chefer et al. pour visualiser les parties d'une image qui contribuent le plus à une prédiction ViT. Nous avons affiné un modèle ViT pour classifier entre 41 maladies de la peau. Ensuite, nous avons montré que même si certaines images contiennent beaucoup d'informations de fond, seule la région de la peau affectée contribue à la décision du modèle. Ces visualisations montrent aux dermatologues quelle partie de l'image le modèle utilise pour prendre une décision. Elles les aident à faire confiance à un modèle et à mieux comprendre les solutions d'IA qu'ils utilisent.
Références
[1] Explainable-AI and machine learning in Healthcare and wellness : Défis, opportunités et avenir. Frontiers. (s.d.). Consulté le 24 août 2022 à l'adresse https://www.frontiersin.org/research-topics/30823/explainable-ai-and-machine-learning-in-healthcare-and-wellness-challenges-opportunities-and-future#overview.
[2] Chefer, H., Gur, S., & Wolf, L. (2021). L'interprétabilité des transformateurs au-delà de la visualisation de l'attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 782-791).
[3] Boesch, G. (2022). Transformateurs de vision (ViT) en reconnaissance d'images - Guide 2022.
[4] Hila-Chefer. (n.d.). Hila-chefer/transformer-explainability : [CVPR 2021] GitHub. https://github.com/hila-chefer/Transformer-Explainability
[5] Rwightman. (2022, 24 juillet). Pytorch-image-models/vision_transformer.py. GitHub. https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py